






🛡️ Giám sát & Quản trị Hệ Thống
Lợi ích cốt lõi
- ⚡ Giảm MTTD/MTTR: phát hiện & khôi phục nhanh hơn.
- 📈 Hiệu năng ổn định: theo dõi p95/p99, throughput, IOPS.
- 🧩 Minh bạch vận hành: dashboard “một cửa” (single pane of glass).
- 🔒 An toàn – tuân thủ: log/audit, phân quyền RBAC, masking PII.
- 💸 Tối ưu chi phí: right-sizing tài nguyên, tối ưu lưu log/metrics.
🏗️ 2) Kiến trúc quan sát (Observability) thực chiến
🧱 Ba trụ cột + bổ sung
- 📊 Metrics: CPU/RAM/IOPS, độ trễ p50/p95/p99, error rate, queue length.
- 📜 Logs: ứng dụng, hệ điều hành, thiết bị mạng, bảo mật.
- 🔍 Traces: theo dõi hành trình request qua nhiều dịch vụ (distributed tracing).
- 🤖 Synthetic: health check chủ động (HTTP, ping, giao dịch giả lập).
- 👥 RUM: đo trải nghiệm người dùng thực (web/app).
🧭 Dòng dữ liệu tổng quát
Clients/Agents/SNMP → 📮 Collector/Proxy → 🧵 Message Bus (tùy chọn) → 🕵️ Xử lý/Chuẩn hóa → 🗃️ Time-series DB + Log Store → 📊 Dashboard/Alert → 📣 Thông báo/On-call → 🤖 Tự động khắc phục.
Nguyên tắc vàng
- 🔁 HA mọi tầng: collector, core, DB, dashboard.
- 🧩 Tiêu chuẩn mở: SNMPv3, IPMI/Redfish, OpenTelemetry, HTTP API.
- 🧪 Test failover định kỳ: chaos nhỏ, diễn tập DR.
🧭 3) Phạm vi giám sát theo lớp (đủ sâu – không thừa)
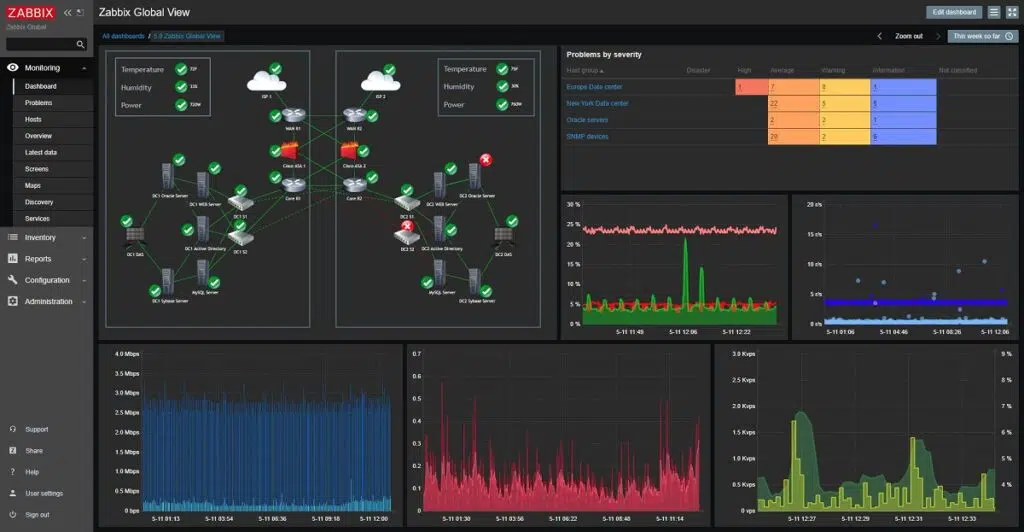
- 🖧 Mạng: router, firewall, switch, VPN, WAN jitter/loss, BGP/OSPF.
- 🖥️ Máy chủ & ảo hóa/K8s: node/pod, HPA, restart count, daemonset.
- 💾 Lưu trữ/Backup: SAN fabric A/B, multipath, IOPS/latency, snapshot/replication, RPO/RTO.
- 🗃️ CSDL: QPS, slow queries, replication lag, lock/deadlock.
- ⚙️ Ứng dụng/Middleware: API latency, error rate, queue (Kafka/RabbitMQ), cache hit.
- 🔐 Bảo mật: đăng nhập bất thường, WAF, EDR/AV, IAM, chứng chỉ.
- 🧊 Cơ sở hạ tầng DC: điện/UPS, nhiệt/ẩm, rò nước, camera (nếu tích hợp BMS).
🚨 4) Thiết kế cảnh báo “ít mà chất” (chống ồn)
Nguyên tắc cài đặt trigger
- ⏱️ for-duration: chỉ báo khi vi phạm liên tục X phút.
- 🔁 Hysteresis: ngưỡng tăng/giảm khác nhau, chống dao động.
- 🧠 Kết hợp điều kiện: latency và error rate và RPS.
- 🧷 Dependencies: link core down → đừng mưa cảnh báo ở access.
- ⛔ nodata() cẩn trọng: chỉ dùng với window hợp lý.
Mẫu quy tắc mang đi dùng ngay
- 🟥 API Degraded (P1): p95 > 800ms và 5xx > 1% trong 5 phút và RPS > baseline.
- 🟧 Disk Full (P2): free < 10% trong 10 phút (kèm runbook xóa log cũ).
- 🟥 DB Replica Lag (P1): lag > 60s trong 2 phút.
- 🟥 WAN Link Down (P1): IF status = down > 60s.
- 🟨 Cert sắp hết hạn (P3→P2): < 21 ngày (cảnh báo sớm), < 7 ngày (nâng cấp mức).
Escalation
- ⏩ Chưa ACK sau 5–10 phút → escalate L2/L3.
- 🔗 Gắn runbook link và owner theo tag
service/team/site. - 📲 Kênh: ChatOps (Slack/Telegram), SMS/voice cho P1, tự tạo ticket ITSM.
🎯 5) SLO/SLI & Error Budget (nói chuyện bằng số)
- 📌 SLI: tỉ lệ request 2xx/3xx; p95 latency; tỷ lệ giao dịch thành công.
- 🎯 SLO: ví dụ API thanh toán 99.95%/tháng.
- 🧮 Error Budget = 0.05% downtime hợp lệ/tháng.
- 🛑 Hết budget sớm → đóng băng thay đổi, ưu tiên độ tin cậy.
🔁 6) Không downtime: chiến lược tổng hợp
🏛️ Kiến trúc HA theo lớp
- 🧩 Ứng dụng: multi-AZ, nhiều instance sau LB L7; blue-green/canary, feature flag.
- 🗃️ CSDL: cluster/replication; failover tự động có kiểm soát; backup + test restore định kỳ.
- 💾 Lưu trữ: dual controller, multipath, snapshot + async/sync replication.
- 🖧 Mạng: dual uplinks, VRRP/HSRP, MLAG/VPC; route failover (IP SLA).
- 🧪 Chaos nhỏ: rút 1 link, down 1 node theo lịch để kiểm chứng runbook.
🛠️ Tự động hóa khắc phục (Auto-remediation)
- 🔁 Restart service khi health fail X lần (có backoff).
- 🧹 Disk đầy → rotate log > N ngày; mở rộng volume nếu được.
- 📈 Scale out tạm thời khi queue/latency vượt ngưỡng.
- 🔐 Cert gần hết hạn → tự gia hạn (ACME), reload LB/Gateway.
- 🧯 Guardrail: log đầy đủ, rate-limit hành động tự động, dừng nếu lặp.
🧑🤝🧑 7) Tổ chức vận hành: NOC – SRE – DevOps – SecOps
- 🛰️ NOC (L1): theo dõi, phân loại, chạy runbook, chuyển cấp.
- 🧠 SRE (L2): định nghĩa SLO/SLI, thiết kế quan sát, tự động hóa.
- 🧑💻 DevOps/App Owner (L3): chịu trách nhiệm dịch vụ, phối hợp RCA.
- 🛡️ SecOps: SIEM/EDR/WAF, xử lý cảnh báo bảo mật.
On-call rõ ràng, thời gian đáp ứng P1/P2/P3; status page cho khách hàng nếu cần.
🔄 8) Quy trình chuẩn: Incident – Problem – Change – Release
- 🆘 Incident: phát hiện → phân loại (P1/2/3) → giảm thiểu/rollback → khôi phục → cập nhật stakeholder.
- 🕵️ Problem: gom sự cố lặp → RCA gốc (kỹ thuật/quy trình) → action items có deadline.
- 🔁 Change: RFC mô tả rủi ro, kế hoạch rollback; maintenance đúng giờ thấp tải; guardrail alerts hậu deploy.
- 📝 Postmortem “không đổ lỗi”: tóm tắt, timeline, nguyên nhân gốc, bài học, việc cần làm (có chủ & ngày hạn).
🔐 9) Bảo mật & tuân thủ trong giám sát
- 🪪 RBAC/SSO: quyền theo vai trò/nhóm; audit mọi thay đổi.
- 🔑 Mã hóa: TLS đường truyền telemetry; encrypt-at-rest; xoay vòng secret/token.
- 🙈 PII/nhạy cảm: masking/pseudonymization; retention hot/warm/cold.
- 🧱 Zero-Trust nội bộ: micro-segmentation (VLAN/VRF), NAC/802.1X, mTLS agent↔collector (khi khả thi).
- 📦 Immutable: WORM/Object Lock cho log/backup quan trọng.
- 📜 Tuân thủ: giữ log 90–365 ngày; đáp ứng audit.
📉 10) Capacity Planning & tối ưu chi phí

- 📊 Thu thập xu hướng 3–12 tháng: CPU/RAM p95, IOPS/latency, disk growth, RPS.
- 🔮 Cảnh báo dự báo: “/data > 85% trong 10 ngày”.
- ✂️ Right-sizing: so p95 với limit, cắt over-provision.
- 🧹 Tối ưu log/metrics: sampling, loại nhiễu, hot 7–14 ngày, warm 30–90, cold 180–365.
- 🧪 Kiểm thử DR: đo RTO/RPO thực tế, diễn tập tối thiểu 6–12 tháng/lần.
📊 11) Dashboard theo đối tượng (ít mà sâu)
- 🧑💼 Executive: SLA theo dịch vụ, error budget, P1 theo tháng, chi phí ước lượng, rủi ro chính.
- 🧑🔧 Service Owner: latency p95/p99, error rate, dependency graph, phiên bản đang chạy, event gần đây.
- 🎛️ NOC: heatmap host/site, proxy queue, cert sắp hết hạn, WAN link.
- 🧠 DB/Storage: replica lag, slow queries; IOPS/latency, path status, snapshot/replication.



